发布时间:所属分类:计算机职称论文浏览:1次
摘 要: 摘 要 基音调制信息隐藏在进行基音预测时嵌入机密信息,可在低速率语音压缩编码过程中进行高隐蔽性的信息隐藏,文中试图对该种隐写进行检测.文中发现该种隐写将导致压缩语音流中相邻语音帧自适应码书的关联特性发生改变,文中以此为设计隐写分析算法的关键线索.为了量
摘 要 基音调制信息隐藏在进行基音预测时嵌入机密信息,可在低速率语音压缩编码过程中进行高隐蔽性的信息隐藏,文中试图对该种隐写进行检测.文中发现该种隐写将导致压缩语音流中相邻语音帧自适应码书的关联特性发生改变,文中以此为设计隐写分析算法的关键线索.为了量化该种关联特性,文中设计了码书关联网络模型并基于该模型得到了对隐写敏感的特征向量.最后,基于所得特征向量并结合SVM(SupportVectorMachine,支持向量机)构建了隐写检测器.针对典型的低速率语音编码标准 G.729以及 G.723.1的实验表明,文中方法性能 优 于 现有检测方法,实现了对基音调制信息隐藏的快速有效检测.
关键词 隐写分析;低速率语音编码器;基音调制信息隐藏;码书关联网络;基音预测
1 引 言
信息隐藏,亦称为隐写术,是一种将秘密信息嵌入到载体中,使秘密信息难于被监管者察觉的技术,载体可以是 文 本、图 像、语 音 以 及 视 频 等 多 媒 体 对象.信息隐藏技术与加密技术的根本区别在于:加密技术使信息呈现为“乱码”而隐藏了信息的内容;信息隐藏技术则更进一步,不仅隐藏了内容还隐藏了信息的“存在性”.与加密技术相比,信息隐藏技术由于可使信息不可察觉,不容易引起攻击者的注意,从而减少了被攻击的概率.由于上述特性,信息隐藏技术可完成某些加密技术无法达成的信息安全任务,例如:可避开监管的隐蔽通信、基于数字水印的版权内容保护、无须带外通道的多媒体内容认证以及完整性验证等.信息隐藏作为一种技术手段也很容易被犯罪分子所使用,例如,美国中情局认为,塔利班在组织美国“911”恐怖活动时,曾使用信息隐藏技术来传递指令和消息.
语音是人类在日常生活中进行交流的主要通信媒介,这就决定了语音必然是一种重要的信息隐藏载体.特别是近年来,随着 VoIP(VoiceoverIP)技术的高速发展———当前因特网中 VoIP年通话流量已超过千亿分 钟 量 级,以 VoIP 通信中的语音码流作为载体的信息隐藏及其检测技术日益受到重视,成为信息隐藏领域新的研究热点[1].在 VoIP 系 统中,为节省带宽资源,多采用基于按合成-分析法的线性预测编码(AnalysisbySynthesis-LinearPredictiveCoding,AbS-LPC)方法的低速率编码器.与简单的基于最低 有 效 位 的 隐 写 方 法 相 比,基 于 AbS-LPC低速率语音编码器进行信息隐藏是一个极具挑战性的问题,其原因是语音经过高压缩比的低速率编码后基本没有冗余数据,很难找到对隐写透明的嵌入位置.鉴于此,很多研究者对这一问题展开了研究.
从现有的 文 献 来 看,基 于 AbS-LPC 低 速 率 语音编码器的信息隐藏方法根据嵌入位置的不同可分为3类.第1类方法主要利用 LPC合成滤波器进行信息隐藏[2-4],具体而言该类方法通过修改 LPC 滤波器系数的分级矢量量化过程进行信息隐藏;第2类方法主要利用音调合成滤波器即基音预测器进行信息隐藏[5-6],具体而言该类方法通过修改基音对应的自适应码本搜索过程进行信息隐藏.上面两类方法都是编码过程中的信息隐藏方法,即将语音压缩和信息隐藏进行集成的信息隐藏算法;第3类方法属于编码后的信息隐藏方法[7-9],该类方法通过修改编码得到的压缩语音码流中的某些特定编码元素达到信息隐藏的目的.
在上述3类方法中,利用基音预测器进行信息隐藏时,通过对自适应码书分组来调整基音的搜索范围,虽然基音的搜索范围被调整,但编码器仍能在一定范围内搜索有限制条件的最优值,这就使其能够保持较好的合成语音质量.而且,由于合成分析过程的存在,搜索过程被修改引入的附加失真,会在后续过程中得到补偿,因此这类方法引入的压缩语音失真极小,具有很高的隐蔽性.
在 VoIP 语 音 信 息 隐 藏 检 测 研 究 方 面,见 诸 报道的一些检测方法大多是在非压缩域提取语音的某些特征进行检测[10-12].这些方法并不能有效地检测压缩语音码流中的信息隐藏,其原因是,压缩域的信息隐藏在解码的语音信号中引入很小的附加失真,因此在非压缩域很难获得能够区分是否隐写的特征.近期已有一些学者专门针对压缩语音中的信息隐藏检测问题开展了相关研究[13-15].最近,文献[15]提出了一种低速率编码器 G.723.1中量化索引调制(QIM)隐写的检测算法.该方法从压缩域提取隐写检测特征,达到了很好的检测效果,为压缩媒体流中信息隐藏的检测提供了一种新的思路.但该方法并不能用于检测基音调制信息隐藏.
基于自适应码书分组的基音调制信息隐藏方法,利用基音预测本身就存在误差,具有极高的隐蔽性,对其进行隐写分析困难极大,迄今尚未有相应的隐写分析方法见诸报道.现有的一些语音隐写分析方法[10-15]也不能直接用于该方法的检测.为此,本文拟对该种方法进行隐写分析.
2 基音调制信息隐藏
基音预测技术是低速率语音编码器中普遍采用的技术.基音调制信息隐藏利用基音预测存在误差,通过对基音预测的结果进行微调达到信息隐藏的目的,对压缩语音质量的影响很小[5-6].VoIP所使用的低速率语音编码标准主要 是 G.723.1和 G.729,针对这两种编码器的基音调制信息隐藏都是通过改变自适应码书的搜索范围来实现的,但又稍有不同,下面将针对上述两种主要的低速率编码器分别介绍其基音调制信息隐藏方法.
G.723.1编码器对每个具有240个样值的帧进行操作,这在8kHz采样速率时相当于30ms,每一帧又被分为具有60个样值的四个子帧.每帧计算两个开环基音估计,一个对前两个子帧,一个对后两个子帧.开环基音 周 期 估 计 LOL 是采用感知加权的语音f[n]来计算的.
由于语音清浊音切换等原因,基音周期检测算法本身就很难达到精确,因此对基音预测的结果进行微调,对压 缩 语 音 质 量 的 影 响 小.最 新 的 研 究 表明,使用上述方法进行信息隐藏后,对原基音周期的改变率低于3%,这 种 等 级 改 变 基 本 不 影 响 解 码 合成语音的质量,具有极高的隐蔽性.这也导致了对该类方法进行隐写分析具有较大的难度.
3 隐写检测算法
语音信号局部存在周期性,特别是浊音音素对应的语音片段,从图1浊音音素“o”对应的语音片段可以非常清楚地看到这一点.
通常浊音 音 素 的 发 音 时 间 在30ms~50ms左右,而在 G.723.1编 码 器 中 基 音 预 测 的 子 帧 时 长 为7.5ms,在 G.729编 码 器 中 基 音 预 测 的 子 帧 时 长 为5ms.因此如果相 邻 子 帧 语 音 信 号 正 好 是 周 期 性 重复的信号,那么这些相邻子帧基音预测所得的值应该是相同的.也就是说,相邻子帧的自适应码书参量具有关联性.
在典型的低速率编码器 G.723.1和 G.729中,自适应码书参量就是基音延迟和增益.基音调制信息隐藏时,基音延迟的取值将依据当前嵌入的秘密比特是0还是1,将其原来的取值调整为奇数或 偶数,这将不可避免地导致相邻帧基音延迟的值发生改变,从而导致相邻帧基音延迟的共生特征被破坏.因此,可以利用这种共生特征进行隐写检测.下面我们给出基于这一思路的隐写分析过程.
3.1 码书关联网络模型的构建
在低速率语音编码器中,每个语音帧被分为多个子帧.如上文所述,语音信号具有局部周期性,因此不同帧的各个子帧的基音延迟具有关联性,即帧间自适应码书参量具有关联性;此外,同一帧内不同子帧的基音延迟同样具有关联性,即帧内自适应码书参量也具有关联性.为了描述这种关联特性,本文定义了码书关联网络这一模型.本文引入的码书关联网络是由顶点和边组成的,顶点表示语音片段中的自适 应 码 书 参 量 (为每个码书参 量创建一个顶点),边表示其所连接的自适应码书参量之间的关联关系.
下面将根据帧内和帧间关联网络模型,针对两种主要的 低 速 率 编 码 器 G.723.1与 G.729,分 别 构建其帧内和帧间码书关联网络.
3.1.1 G.723.1码书关联网络
在 G.723.1中,基音预测的结果是用自 适 应 码书滞后和差分自适应码书滞后来表示的,压缩语音码流的参量中,ACL0和 ACL2为第0、2子帧的自适应码书滞后,用7bit编 码;ACL1和 ACL3为 第1、3子帧的差分自适应码书滞后,用2bit编码.在由 上述关联网络模型 构 建 G.723.1码 书 关 联 网 络 时,为了去除关联网络中相关性较弱的顶点以及便于计算,制定以下规则.
规则1. 不选择两个7bit编码顶点之间的关联关系.7bit编码顶点的取值 范 围 为0~127,那 么相邻两个 顶 点 的 组 合 关 系 有 16384 种.数 据 维 度太高,需要大样本 量 才 能 反 映 出 其 统 计 特 性,难 于实用.因 此,不 选 择 7bit编 码 顶 点 之 间 的 关 联关系.
相关知识推荐:论文发表期刊真假辨别方法
规则2. 任意两个网络 顶 点 之 间 的 时 间 距 离小于或 等 于 30ms.其原因是通常浊音音素的发音时间在30ms~50ms左右,很明显,在30ms~50ms这个范围内,网络顶点之间的时间距离越大,周期性越不明显.为了提高关联网络的准确性,我们选择网络顶点之间的时间距离小于或等于30ms.
根据上面两个规则,可以得到 G.723.1帧 间 和帧内码书关联网络,如图4和图5所示.为了方便描述,我们将关联网络中的有向边用a,b,c,d,e,f,g,m,n,p,q标定,见图4和图5.
3.1.2 G.729码书关联网络
在 G.729中,基音预测的结果是用 基音延迟P1和 P2来 表 示 的,其 中 第 1 子 帧 基 音 延 迟 P1用8bit编码,第2子帧基音延迟P2用5bit编码.在构建 G.729关联网络时,制定以下规则.
规则3. 不选择两个8bit编码顶点之间的关联关系.其原因是8bit编码顶点的取值范围为0~255,相 邻 两 个 8bit编码顶点的组合关 系高达65536种,维度如此之高的数据其统计特性非常难于获取,即很难观察到其关联特性.
根据规则3,并将关联网 络 中 的 每 条 有 向 边 用u,v,w,x标 定,可 以 得 到 G.729 帧间和帧内码书关联网络如图6和图7所示.
3.2 码书关联网络的剪枝
在上文 中,我们通过制定相应的规 则去除了关联网络中相关性较弱的顶点,从 而 得 到 了 两 种低速率编码器对应的帧内和帧 间码书关联网络.但是,所得关联网络仍然过于 复杂而不便于量化定点间的关联关 系.为 此,在 本 部 分 我 们 将 给 出 一种对关联网络进行剪枝的方法.经 过 剪 枝 处 理 的原始关联 网 络,将只保留帧内 和帧间关联网络中相关性最 强 的 顶 点,并 通 过 融 合 得 到 一 体 性 强 相关性网络.以下将仍以两种典 型的低速率语音编码器 G.723.1 和 G.729 为 例,阐 述 关 联 网 络 剪 枝方法.
3.2.1 G.723.1码书关联网络的剪枝
语音信 号 的 局 部 周 期 性,使 得 相 邻 子 帧 的 自适应码书 参 量 具 有 关 联 性.因 此 可 以 通 过 比 较 基音延迟相 同 的 顶 点 的 数 量,选 出 帧 内 和 帧 间 关 联网络中相关性最强的顶点.定义 G.723.1相关性指数如下:
4 实验结果
本文选择 G.723.1和 G.729作为实验测试所用的低速率语音编码器,并采用文献[5-6]给出的基音调制信息隐藏方法作为隐写方法,进行了本文隐写检测方法的性能评估.文献[12]是近年公开的比较有效的语音隐写分析方法,被文献[5-6]用于评估其算法性能,因此我们也将本文方法与文献[12]给出的隐写检测方法进行了比较.
为了阐明本算法具有较好的普适性,本文选择不同发音人的多个语音片段组成语音样本库.所用语音片段样本包含5种,分别是中文男声(ChineseSpeech Man,CM),中 文 女 声 (Chinese SpeechWoman,CW),英 文 男 声 (English Speech Man,EM),英 文 女 声(EnglishSpeech Woman,EW),每种语音样本各包含1000个语音片段;第5种为上述4类样本的 混 合(Hybrid),共 有4000个 语 音 片 段.每个语音片段时长为30s,采 样 率 为8000Hz,每 个采样点用16bit量化,用 PCM 格式存储.
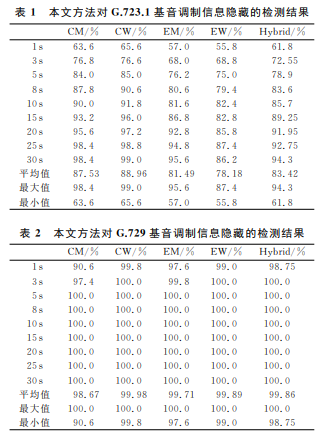
为了评估训练所得分类器的分类准确性,用上述5种语音样本的隐写和未隐写的压缩语音片段分别组成训练样本和测试样本,每类样本75%用于训练,25%用于测试,并提取其特征向量.然后用训练样本的特征向 量 对 SVM 分 类 器 进 行 训 练,用 训 练好的SVM 分类器对测试样本进行分类并计算分类准确率.同时,我们还评估了语音片段时长对隐写检测结果的影响.表1和表2给出了用本文检测方法对5种语音样本在9种时长下的隐写检测结果.
文献[5-6]采用了基于二阶差分衍生梅尔倒谱系数(Derivative Mel-FrequencyCepstralCoefficients,DMFCC)特征的通用隐写分析方法[12],对其隐写算法的性能进行了评估.这种隐写分析方法是近年来提出的比较重要的隐写分析方法,能够对多种语音隐写算法达到较好的检测效果.因此,为了更好的评价本文方法性能,本文做了两种算法的对比实验.使用相同的语 音 样 本 库,DMFCC 方法的隐写检测结果如表3和表4所示.——论文作者:李松斌1)贾已真2)付江云1)戴琼兴1)